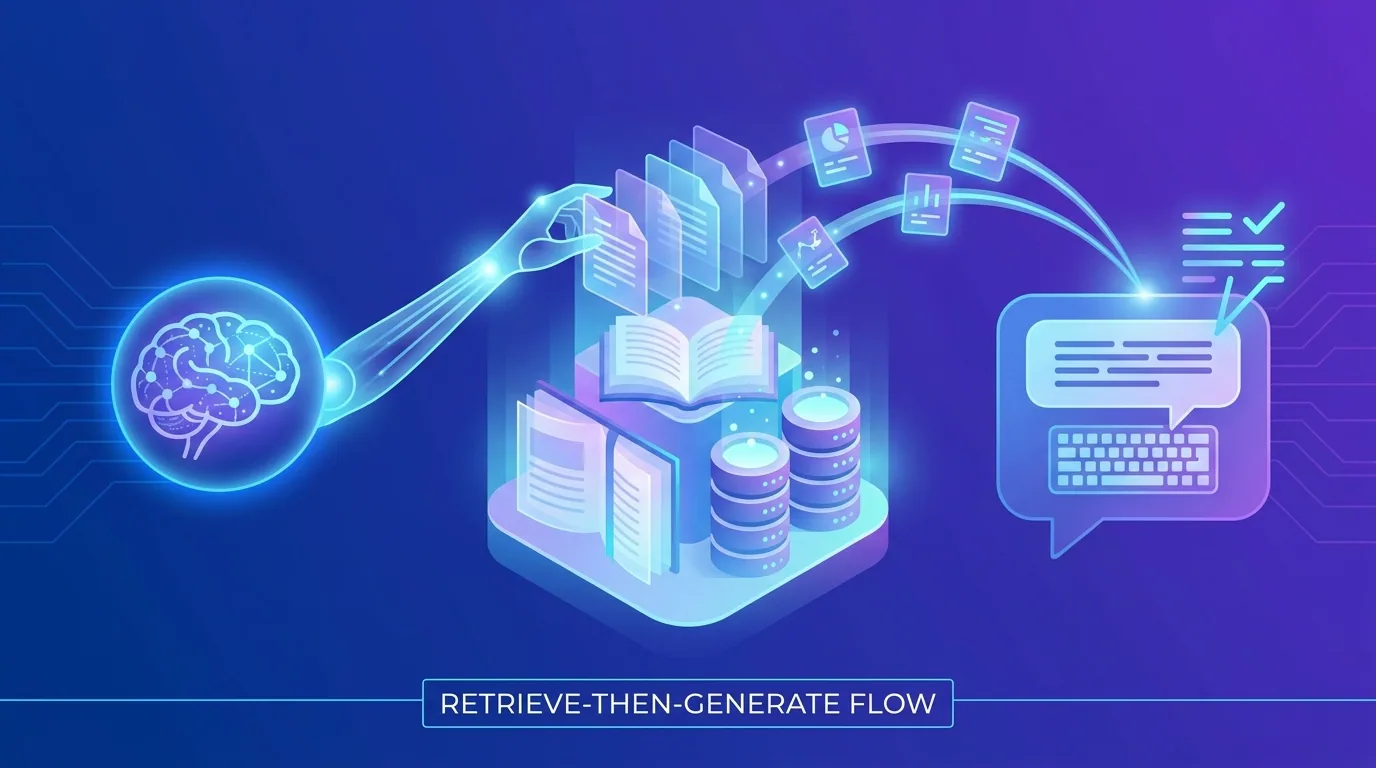
Retrieval-augmented generation, or RAG, is a technique that lets an AI model answer questions using your own up-to-date documents instead of relying only on what it memorised during training. Before answering, the system retrieves the most relevant passages from your knowledge base — policies, product docs, past tickets — and hands them to the model as context, so the reply is grounded in your facts. For most businesses in 2026, RAG is the fastest, cheapest, and most controllable way to put a trustworthy AI on top of their own information.
If you have ever watched a generic chatbot confidently invent an answer, RAG is the fix. This guide explains what RAG is in plain language, how it compares to fine-tuning, where it shines, and how we build it into the AI agents we deliver. No maths degree required.
What is retrieval-augmented generation?
RAG combines two steps: retrieval and generation. When a question comes in, the system first searches a knowledge base for the most relevant chunks of information, then feeds those chunks to a language model along with the question. The model writes its answer using that supplied context rather than guessing from memory. The result is an answer rooted in your real, current data.
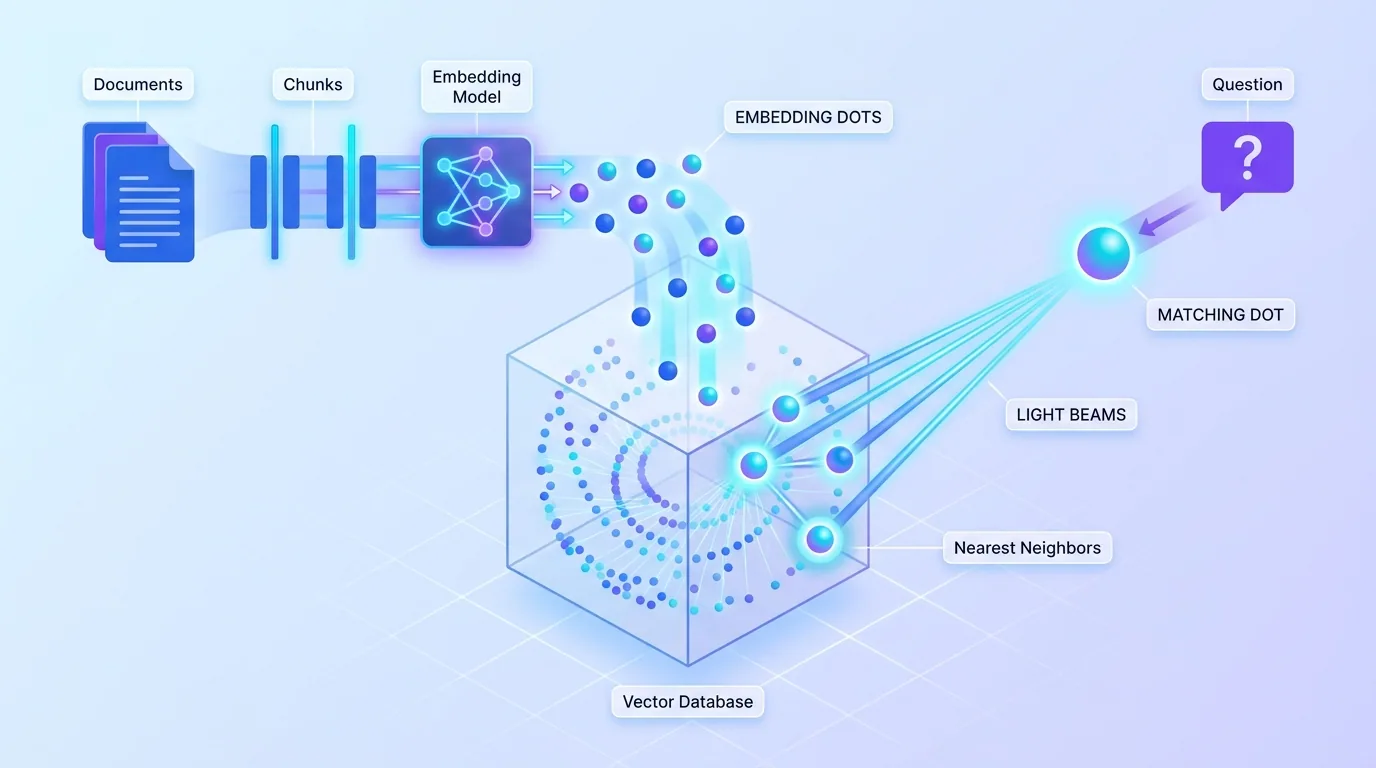
The magic is in how the search works. Your documents are split into chunks and converted into embeddings — numerical fingerprints of meaning — stored in a vector database. When a question arrives, it is turned into an embedding too, and the system finds the chunks whose meaning is closest. This is why RAG can find the right passage even when the question uses completely different words than the document.
A helpful analogy: imagine a brilliant new employee who is a superb writer and reasoner but has never read your company's files. Fine-tuning is like sending that employee on a long training course to change how they think. RAG is like giving them an instant, searchable library and letting them look up the right page before they answer. For questions about your specific business, the library approach is faster, cheaper, and far easier to keep current.
Why do businesses need RAG?
Out of the box, a language model knows a lot about the world but nothing about *your* world — your pricing, your policies, your products, your customers. Worse, when it does not know something, it may hallucinate a plausible-sounding but wrong answer. RAG solves both problems at once by grounding every answer in documents you control.
That grounding unlocks the use cases businesses actually want: a support agent that answers from your real help docs, an internal assistant that knows your handbook, a sales tool that quotes your current pricing. Because the answer is tied to a source, you can even show citations — which builds the trust that makes people use the tool in the first place.
- Accuracy: answers come from your documents, not the model's fuzzy memory.
- Freshness: update a document and the AI knows the new fact immediately — no retraining.
- Trust: responses can cite the exact source, so users can verify and audit them.
- Privacy: sensitive data stays in your controlled store and is retrieved only when needed.
RAG vs fine-tuning: which should you use?
This is the question we get most often, and for most businesses the answer is RAG. Fine-tuning retrains a model on your data to change how it behaves — useful for teaching a consistent style, format, or specialised task. RAG gives a model access to your knowledge at the moment of answering — useful for facts that change and must be accurate. They solve different problems.

- Use RAG when answers depend on facts that change, must be accurate, or need to cite a source — the vast majority of business cases.
- Use fine-tuning when you need a consistent tone, a specialised output format, or a narrow repetitive task the base model handles poorly.
- Use both when you want a model that behaves exactly how you like (fine-tuned) and answers from current data (RAG) — increasingly the gold standard for serious deployments.
The practical takeaway: start with RAG. It is faster to build, cheaper to maintain, and easy to update. Reach for fine-tuning only once you have a clear need for behaviour the base model cannot deliver — and even then, RAG usually stays in the picture for the facts.
How do you build a RAG system in 2026?
A production RAG system follows a clear pipeline, and most of the engineering effort goes into the unglamorous parts: clean data and smart chunking. Get those right and the rest follows. The headline steps are ingest, embed, retrieve, and generate — with quality controls layered on top.
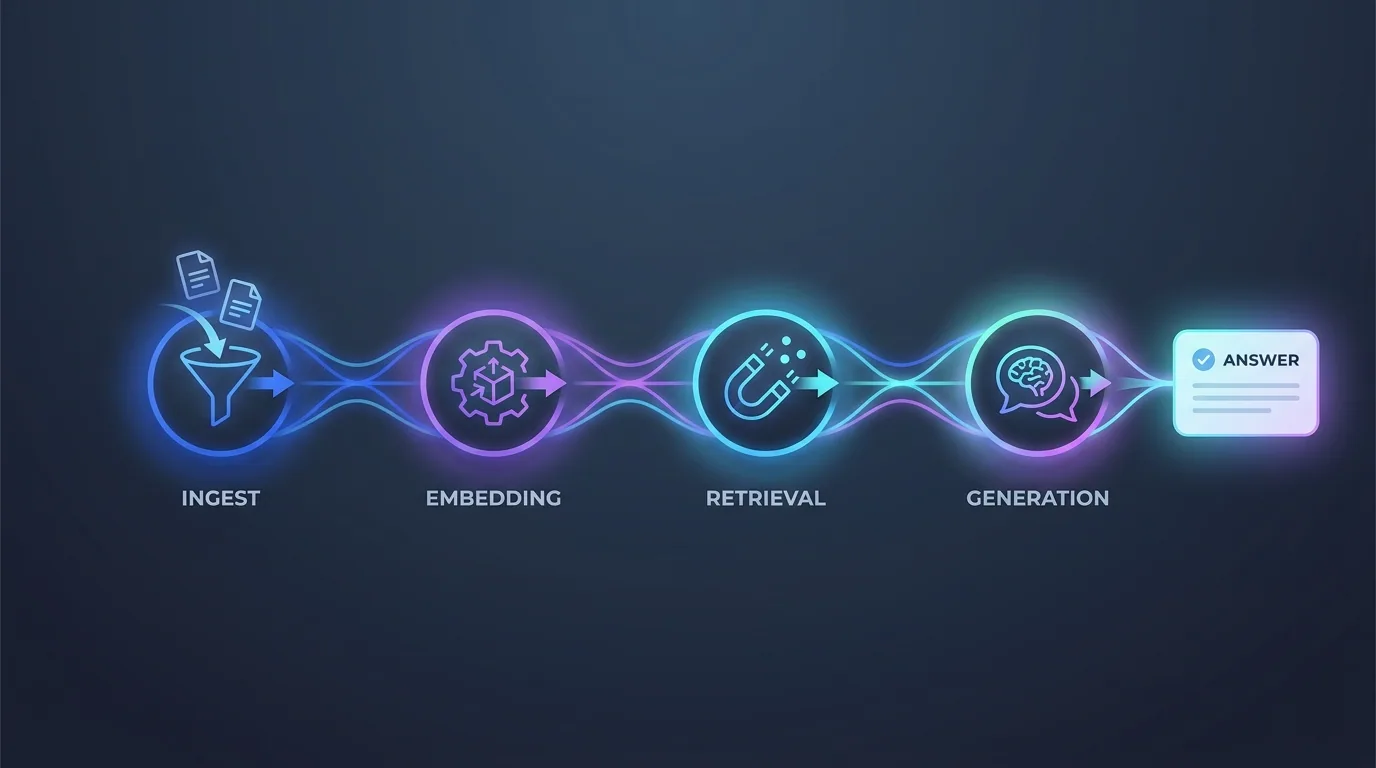
- Ingest and chunk: gather your documents and split them into meaningful, right-sized passages.
- Embed: convert each chunk into an embedding and store it in a vector database.
- Retrieve: at query time, find the most relevant chunks for the question.
- Generate: pass those chunks to the model with clear instructions to answer only from the provided context.
- Cite and guardrail: return source links and instruct the model to say "I do not know" when the context lacks an answer.
That final guardrail is what makes RAG trustworthy. A well-built system answers "I do not have that information" rather than inventing something — and in many setups, RAG is the engine behind a customer-facing AI agent or an internal assistant connected to your tools through the Model Context Protocol (MCP).
Most AI projects do not fail on the model — they fail on the data. Clean, well-chunked, well-retrieved knowledge is ninety percent of a RAG system that businesses actually trust.
— Priya Nair, AI Solutions Architect, Fryntavo
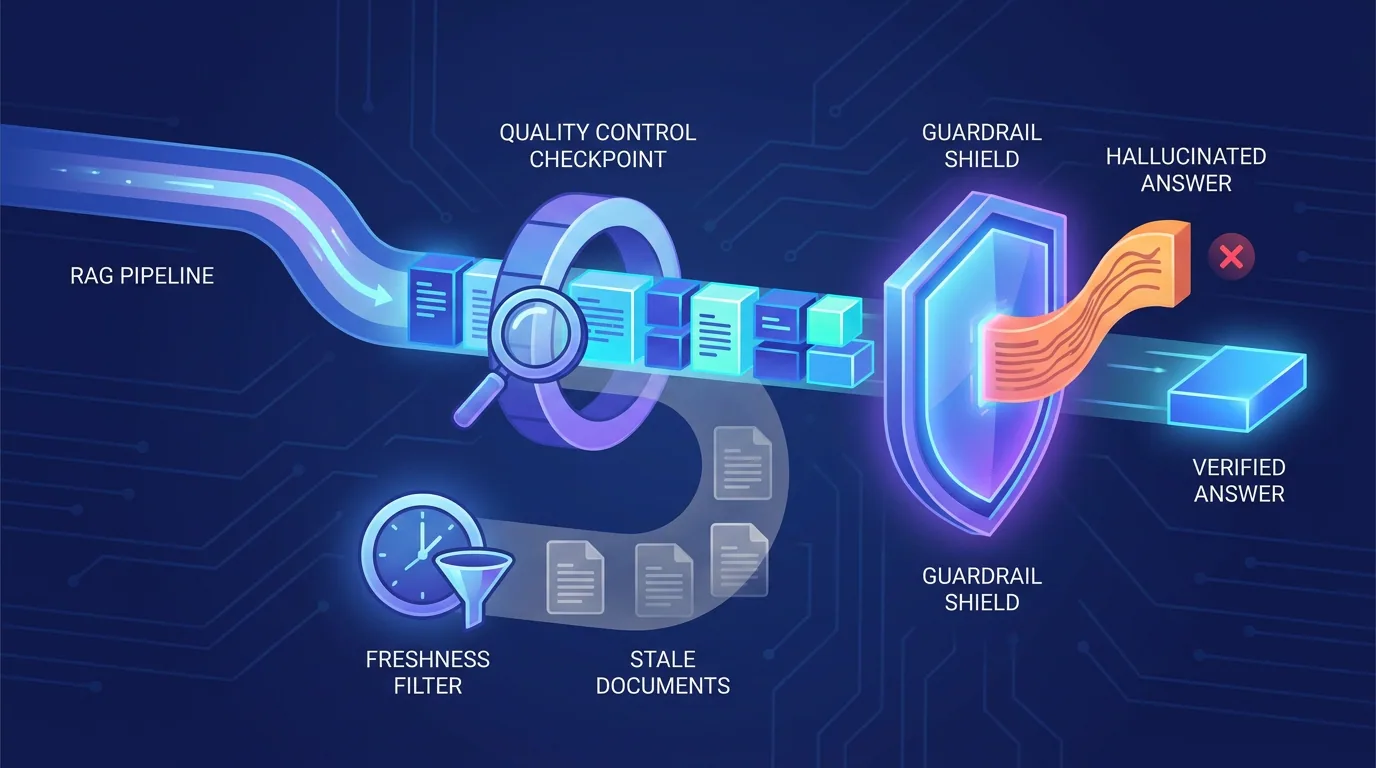
What are the common RAG mistakes to avoid?
RAG is powerful but not plug-and-play, and the failure modes are predictable. Poor chunking splits answers across boundaries so retrieval misses them. Stale or duplicated documents poison results. And skipping the "answer only from context" instruction invites the hallucinations RAG was meant to prevent. The good news is that each of these is fixable with discipline rather than genius.
Another underrated mistake is retrieving too little or too much. Pull back only one tiny chunk and the model may miss the surrounding detail it needs; pull back twenty chunks and you drown the real answer in noise and inflate your costs. Tuning how many passages you retrieve, and re-ranking them so the most relevant rise to the top, is often the single highest-leverage improvement you can make once the basics are working.
The bottom line on RAG for business
Retrieval-augmented generation is the most practical way to make AI useful for your business: it grounds answers in your own current data, cites its sources, updates in minutes, and avoids the hallucinations that erode trust. For most companies it beats fine-tuning as a starting point, and it powers everything from support agents to internal assistants. Invest in clean data and smart retrieval, add a firm "only answer from context" guardrail, and you will have an AI you can actually rely on.
Want an AI agent that answers from your own knowledge base — accurately, with citations, and without hallucinating? Our team builds production RAG systems end to end.
Build a RAG-Powered AgentFrequently asked questions
What is retrieval-augmented generation (RAG)?
RAG is a technique that lets an AI model answer using your own documents instead of relying only on its training. Before answering, the system retrieves the most relevant passages from your knowledge base and gives them to the model as context, so the reply is grounded in your real, current facts.
What is the difference between RAG and fine-tuning?
RAG gives a model access to your knowledge at answer time, which is ideal for facts that change and must be accurate. Fine-tuning retrains a model to change its behaviour, style, or format. RAG teaches what to know; fine-tuning teaches how to behave, and many advanced systems use both.
Should my business use RAG or fine-tuning first?
Start with RAG. It is faster to build, cheaper to maintain, and easy to update because you simply change the documents. Reach for fine-tuning only when you need consistent behaviour, tone, or output format that the base model cannot deliver, and RAG usually stays in the picture for facts.
Does RAG stop AI from hallucinating?
It dramatically reduces hallucinations by grounding answers in retrieved documents and instructing the model to answer only from that context. A well-built RAG system will say it does not have the information rather than inventing an answer, which is what makes it trustworthy for business use.
What is a vector database in RAG?
A vector database stores your documents as embeddings, which are numerical fingerprints of meaning. When a question arrives, it is also turned into an embedding, and the database finds the chunks whose meaning is closest. This lets RAG retrieve the right passage even when the question uses different words than the document.
How quickly can RAG learn new information?
Almost instantly. Because RAG separates knowledge from the model, you simply add or update a document in the knowledge base and the AI can use the new fact right away. There is no model retraining, which is a major advantage over fine-tuning for information that changes often.
What are the most common RAG mistakes?
The most common problems are poor chunking that splits answers across boundaries, stale or duplicated documents that pollute results, and forgetting to instruct the model to answer only from the provided context. Each is fixable with disciplined data hygiene and clear guardrails rather than advanced engineering.
Can RAG cite its sources?
Yes. Because each answer is built from specific retrieved chunks, a RAG system can return links to the exact documents it used. Source citations let users verify and audit answers, which builds the trust that encourages people to actually adopt the tool.
Ready to put this into action?
Fryntavo helps brands grow with web development, SEO, marketplace management, and AI automation. Book a free, no-obligation strategy call.
Book a Free Strategy Call